Changing the first disk and my case to Synology support
Now it was time to replace the first disk. As I assumed this would never go wrong (!) and did not plan to document the upgrade, I did not take out any information about the partitions, mdraids and volumes during this first disk swap.
The instructions from Synology are quite good for this (until something breaks down):
Replace Drives to Expand Storage Capacity
Basically it says: replace the disks one by one, start with the smallest and wait until completion before replacing the next.
For the first disk swap, I actually shut down my DS1517 before replacing the disk (many models, including DS1517, supports hot swapping the disks). When the disk was replaced and I powered up the DS1517, and as expected I got the “RAID degraded” beep.
Did a check that the new drive was recognized, and then started the repair of the storage pool. As this will usually take many hours, and this was done in the evening, I have no idea of the actual time spent for repairing (rebuilding) the pool. This was about 90% finished when I stopped looking at the status around midnight that day.
The next day, I see that it had “restarted” (lower percentage than yesterday), but this is actually the next step that is initiated directly after repairing the pool. It’s called “reshaping” and during that process other mdraids are changed and adjusted (if possible) against the new disk.
Changes during the first disk swap
These are only assumptions, because I did not take enough info in between swapping the disk and until about a third into reshaping.
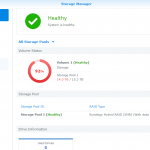
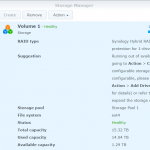
At the point of changing the first disk (refer to the previous part of my article), my storage pool/volume consisted of two mdraids joined together:
md2: RAID 5 of sda5, sdb5, sdc5, sdd5, sde5: total size about 11.7TB
md3: RAID 1 of sdd6, sde6: total size of about 4.8TB
When I pulled the first drive (3TB) and replaced it with a 14TB drive, I assume the partition table on that disk was created like this (status pulled from the mid of reshaping after first disk swap, so I’m pretty sure this is correct):
/dev/sda1 2048 4982527 4980480 fd
/dev/sda2 4982528 9176831 4194304 fd
/dev/sda5 9453280 5860326239 5850872960 fd
/dev/sda6 5860342336 15627846239 9767503904 fd
sda5 was matched up with the size of the old sda5 (and the ‘5’-partitions on the other disks)
sda6 was also created in either the step before rebuild, or right before reshaping (this partition match the size with the ‘6’-partitions on sdd and sde.
Because the (14T) disk is larger than the previous largest (8TB) one, there are some non-partitioned wasted space (about 5.8TB which will come into use after the next disk swap).
Reshaping
Again, I have not taken any full status dumps so that my information can be confirmed, but this is what I see afterwards, and adding my guesses to it because of the better logging of later disk swaps.
After the storage pool was repaired, reshaping started automatically. During this step, the RAID1 consisting of sdd6 and sde6 (md3) were changed into RAID5 consisting of sda6, sdd6 and sde6.
At about 30% into the reshaping phase, my NAS went unresponsive (disconnected both shell and GUI), and I had to wait all day until I came home and did a hard reset on it and hoped everything went well..
In the meantime, I logged a case to the Synology support (see “Part 2b” of this article). They were not of any direct help, and the hard reset did take the NAS back to continuing the reshaping process.