Another Seagate drive failed
Yesterday, when I had the JotteCloud client started to backup the content of the shares on one of my LS220s, I noticed a slowdown in reading files from that device.
Checking the dmesg output I found a repeating pattern of IO errors
end_request: I/O error, dev sda, sector 1231207416
ata1: EH complete
ata1.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6
ata1.00: edma_err_cause=00000084 pp_flags=00000001, dev error, EDMA self-disable
ata1.00: failed command: READ DMA EXT
ata1.00: cmd 25/00:08:f8:bb:62/00:00:49:00:00/e0 tag 0 dma 4096 in
res 51/40:00:f8:bb:62/40:00:49:00:00/00 Emask 0x9 (media error)
ata1.00: status: { DRDY ERR }
ata1.00: error: { UNC }
ata1: hard resetting link
ata1: SATA link up 3.0 Gbps (SStatus 123 SControl F300)
ata1.00: configured for UDMA/133
ata1: EH complete
ata1.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6
ata1.00: edma_err_cause=00000084 pp_flags=00000001, dev error, EDMA self-disable
ata1.00: failed command: READ DMA EXT
ata1.00: cmd 25/00:08:f8:bb:62/00:00:49:00:00/e0 tag 0 dma 4096 in
res 51/40:00:f8:bb:62/40:00:49:00:00/00 Emask 0x9 (media error)
ata1.00: status: { DRDY ERR }
ata1.00: error: { UNC }
ata1: hard resetting link
ata1: SATA link up 3.0 Gbps (SStatus 123 SControl F300)
ata1.00: configured for UDMA/133
ata1: EH complete
ata1.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6
ata1.00: edma_err_cause=00000084 pp_flags=00000001, dev error, EDMA self-disable
ata1.00: failed command: READ DMA EXT
ata1.00: cmd 25/00:08:f8:bb:62/00:00:49:00:00/e0 tag 0 dma 4096 in
res 51/40:00:f8:bb:62/40:00:49:00:00/00 Emask 0x9 (media error)
ata1.00: status: { DRDY ERR }
ata1.00: error: { UNC }
ata1: hard resetting link
ata1: SATA link up 3.0 Gbps (SStatus 123 SControl F300)
ata1.00: configured for UDMA/133
ata1: EH complete
ata1.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6
ata1.00: edma_err_cause=00000084 pp_flags=00000001, dev error, EDMA self-disable
ata1.00: failed command: READ DMA EXT
ata1.00: cmd 25/00:08:f8:bb:62/00:00:49:00:00/e0 tag 0 dma 4096 in
res 51/40:00:f8:bb:62/40:00:49:00:00/00 Emask 0x9 (media error)
ata1.00: status: { DRDY ERR }
ata1.00: error: { UNC }
ata1: hard resetting link
ata1: SATA link up 3.0 Gbps (SStatus 123 SControl F300)
ata1.00: configured for UDMA/133
ata1: EH complete
ata1.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6
ata1.00: edma_err_cause=00000084 pp_flags=00000001, dev error, EDMA self-disable
ata1.00: failed command: READ DMA EXT
ata1.00: cmd 25/00:08:f8:bb:62/00:00:49:00:00/e0 tag 0 dma 4096 in
res 51/40:00:f8:bb:62/40:00:49:00:00/00 Emask 0x9 (media error)
ata1.00: status: { DRDY ERR }
ata1.00: error: { UNC }
ata1: hard resetting link
ata1: SATA link up 3.0 Gbps (SStatus 123 SControl F300)
ata1.00: configured for UDMA/133
ata1: EH complete
ata1.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6
ata1.00: edma_err_cause=00000084 pp_flags=00000001, dev error, EDMA self-disable
ata1.00: failed command: READ DMA EXT
ata1.00: cmd 25/00:08:f8:bb:62/00:00:49:00:00/e0 tag 0 dma 4096 in
res 51/40:00:f8:bb:62/40:00:49:00:00/00 Emask 0x9 (media error)
ata1.00: status: { DRDY ERR }
ata1.00: error: { UNC }
ata1: hard resetting link
ata1: SATA link up 3.0 Gbps (SStatus 123 SControl F300)
ata1.00: configured for UDMA/133
sd 0:0:0:0: [sda] Unhandled sense code
sd 0:0:0:0: [sda] Result: hostbyte=0x00 driverbyte=0x08
sd 0:0:0:0: [sda] Sense Key : 0x3 [current] [descriptor]
Descriptor sense data with sense descriptors (in hex):
72 03 11 04 00 00 00 0c 00 0a 80 00 00 00 00 00
49 62 bb f8
sd 0:0:0:0: [sda] ASC=0x11 ASCQ=0x4
sd 0:0:0:0: [sda] CDB: cdb[0]=0x28: 28 00 49 62 bb f8 00 00 08 00
end_request: I/O error, dev sda, sector 1231207416
ata1: EH complete
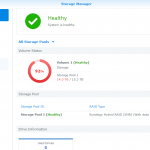
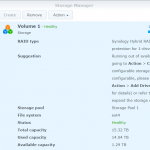
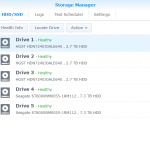
So, this time sda (the first of the two drives) were failing (sdb had been replaced earlier), and as with the other LS220s I run these in RAID0 (stripe) mode, so both drives are needed for proper operation. I do probably have most of the content backed up since the last failure and since the last regular backups to JottaCloud)
As usual, I fired up my computer used for data-rescuing, and as usual it complained that it hadn’t been used for a too-long time, so the BIOS settings had been forgotten. Had to change that back to booting from CD (Trinity Rescue Kit), but probably missed to enable the internal SATA connectors this time.
Running both the source and destination drives on the same controller makes the rescuing a bit slow, but I’ll just let it run.
I stumbled upon errors early on (during copying the system partitions), so I stopped here and investigated what’s going on:
dmesg output on my rescue-system
sd 7:0:0:0: [sdb] CDB: Read(10): 28 00 00 72 b5 e7 00 00 80 00 end_request: I/O error, dev sdb, sector 7517744
This is the layout of the partitions from another LS220s
Number Start End Size File system Name Flags 1 34s 2000000s 1999967s ext3 primary 2 2000896s 11999231s 9998336s primary 3 11999232s 12000000s 769s primary bios_grub 4 12000001s 12000001s 1s primary 5 12000002s 14000000s 1999999s primary 6 14000128s 7796875263s 7782875136s primary
As seen in the dmesg output, the problem was within the second partition, so I restarted ddrescue with the -i parameter to set the start position at start of partition 3 (dealing with 2 later, which is a part of the root filesystem (md1, which consists of sda2 and sdb2) that should be mirrored on the other drive (I have had problems with broken mirrors before, so it might even be that I have no valid copy of this partition).
ddrescue -i 11999232b -d /dev/sdb /dev/sdc /sda1/ddrescue/buff6-1.log
About 12 hours later, I’m almost halfway through the data partition (partition 6) for the mdraid volume. A few errors so far, but ddrescue will get back to those bad parts and try splitting them into smaller pieces later on.
Initial status (read from logfile) rescued: 0 B, errsize: 0 B, errors: 0 Current status rescued: 1577 GB, errsize: 394 kB, current rate: 36765 kB/s ipos: 1583 GB, errors: 3, average rate: 38855 kB/s opos: 1583 GB
I will eventually loose some files here, but the primary goal is to get the drive recognized as a direct replacement for the failed one.
Getting closer…
About 30 hours later, the most of the drive had been copied over to the replacement disk. I saved the errors on the root partition to the last step (which of the final, but most time consuming part is taking place now), where I first copied as much as possible from around where the early errors occured, then getting closer to the problematic section on each additional run.
Initial status (read from logfile) rescued: 4000 GB, errsize: 4008 kB, errors: 83 Current status rescued: 4000 GB, errsize: 518 kB, current rate: 0 B/s ipos: 3828 MB, errors: 86, average rate: 254 B/s opos: 3828 MB Splitting error areas...
I gave it another couple of hours and was ready to abort and test if it would boot.. Then it just finished.
Current status rescued: 4000 GB, errsize: 493 kB, current rate: 0 B/s ipos: 6035 MB, errors: 94, average rate: 2 B/s opos: 6035 MB Finished
Options from here
As I have many backup copies of the content from the NAS this disk is a part of the storage volume on, only a few files (if any at all) will be missing if I restore what I have (have to check and remove duplicates from the backups, but that’s another story), so doing this rescue has already from the beginning only been for educational purposes.
Ignore the 518kB (finished at 493kB) of errors and test if it boots
Before going on, I will create a partial backup image from the drive I recovered the data to, which will be all partitions up to the gap between the system partitions and the beginning of the data partition. The size of the non-data partitions is only about 7GB (14 million blocks) as seen in the partition table:
Number Start End Size File system 1 34s 2000000s 1999967s ext3 2 2000896s 11999231s 9998336s 3 11999232s 12000000s 769s 4 12000001s 12000001s 1s 5 12000002s 14000000s 1999999s 6 14000128s 7796875263s 7782875136s
It’s probably a good idea to not include the start block of the data partition (14000128s), but also safe to skip halfway through the gap between the partitions.
dd if=/dev/sdc of=/sda1/ddrescue/buffa6-1-p1-5 bs=512 count=14000064
This way, I can easily restore the system partitions whenever something goes wrong.
Trying to boot the NAS with the recreated disk and the working one
This is the easiest thing I can try. After running ddrescue from the third partition onwards and until the end, there were only about 40kB unrecoverable data (with or without content). This means that I at least can connect the disks to a Linux machine and mount the mdraid volume there for recovery.
But booting it up in the NAS is the “better” solution in this case.
If booting the disks in the NAS fails
If the NAS won’t boot, my next step will be to try to recover more of the missing content from the root partition (I actually ended up doing this before trying to boot, and was able to recover 25kB more).
Use root partitions from another Buffalo
This would have been my next idea to try out. I have a few more of these 2-disk devices, so I can shut one down and clone the system partitions of both the disks, then dd them back to the disks for “Buffalo 6”. This will give it the same IP as the cloned one, but that’s easy to change if this will make it boot again.
I didn’t have to try this. Can save this for the next crash 🙂
The boot attempt..
Mounted the “new” disk 1 in the caddy, then started up the NAS.. Responds to ping on its IP..
And I was also able to log in to it as “root” (previous modifications to allow SSH root access).. Looking good..
[root@BUFFALO-6 ~]# df -h Filesystem Size Used Available Use% Mounted on udev 10.0M 0 10.0M 0% /dev /dev/md1 4.7G 784.9M 3.7G 17% / tmpfs 121.1M 84.0K 121.0M 0% /tmp /dev/ram1 15.0M 108.0K 14.9M 1% /mnt/ram /dev/md0 968.7M 216.4M 752.2M 22% /boot /dev/md10 7.2T 707.2G 6.6T 10% /mnt/array1 [root@BUFFALO-6 ~]#
mdraid looks OK, except (what I already suspected) that the mirrors for the system partitions were broken (I forgot to fix that the last time I replaced a disk (the other one) in it)..
[root@BUFFALO-6 ~]# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4]
md10 : active raid0 sda6[0] sdb6[1]
7782874112 blocks super 1.2 512k chunks
md0 : active raid1 sda1[0]
999872 blocks [2/1] [U_]
md1 : active raid1 sda2[0]
4995008 blocks super 1.2 [2/1] [U_]
md2 : active raid1 sda5[0]
999424 blocks super 1.2 [2/1] [U_]
Another easy fix..
mdadm --manage /dev/md0 --add /dev/sdb1 mdadm --manage /dev/md1 --add /dev/sdb2 mdadm --manage /dev/md2 --add /dev/sdb5
All mirrored partitions OK now:
[root@BUFFALO-6 ~]# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4]
md10 : active raid0 sda6[0] sdb6[1]
7782874112 blocks super 1.2 512k chunks
md0 : active raid1 sdb1[1] sda1[0]
999872 blocks [2/2] [UU]
bitmap: 0/1 pages [0KB], 65536KB chunk
md1 : active raid1 sdb2[2] sda2[0]
4995008 blocks super 1.2 [2/2] [UU]
bitmap: 1/1 pages [4KB], 65536KB chunk
md2 : active raid1 sdb5[2] sda5[0]
999424 blocks super 1.2 [2/2] [UU]
bitmap: 1/1 pages [4KB], 65536KB chunk