Summary
This post describes how to shorten the time and lessen the wear on the drives of a Synology NAS when replacing all the disks. My method delays the “reshaping” phase until the last drive has been inserted (from where you can let the NAS do its thing) by manually removing the newly created partitions for SHR expansion that is created when each new disk is inserted.
Disk replacement in DS918
Time to fix this device, since there has been a long time since one of the drives in this unit failed (all backed up, I could simply just replace all disks and start over with it).
This unit used the surviving 3TB drives from my DS1517 after two of them had failed, and I later replaced all the disks in that unit to 14TB ones to get more storage space. This is documented in Inner secrets of Synology Hybrid RAID (SHR) – Part 1
I have written a short summary as a reply in this thread on Reddit: Replacing all drives with larger drives, should I expect it to progressively take longer for repairs with each new larger drive that is swapped in?
Another post on this topic in the Synology community forum: Replacing all Disks: Hot Swap & Rebuild or Recreate
Replacing the first drive (the failed one)
To make sure I correctly identified the drive that had to be replaced, I checked logs, raid status and disk status before pulling the drive. As I already knew, /dev/sdd was the one that had failed, so I needed to find out in which slot (as expected, the fourth slot, but this should always be checked) it was fitted in:
dmesg output (filtered)
This confirms the problems with /dev/sdd:
[ 5.797428] sd 3:0:0:0: [sdd] 5860533168 512-byte logical blocks: (3.00 TB/2.73 TiB) [ 5.797439] sd 3:0:0:0: [sdd] 4096-byte physical blocks [ 5.797656] sd 3:0:0:0: [sdd] Write Protect is off [ 5.797666] sd 3:0:0:0: [sdd] Mode Sense: 00 3a 00 00 [ 5.797767] sd 3:0:0:0: [sdd] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA [ 5.869271] sdd: sdd1 sdd2 sdd5 [ 5.870466] sd 3:0:0:0: [sdd] Attached SCSI disk [ 7.851964] md: invalid raid superblock magic on sdd5 [ 7.857051] md: sdd5 does not have a valid v0.90 superblock, not importing! [ 7.857169] md: adding sdd1 ... [ 7.857175] md: sdd2 has different UUID to sda1 [ 7.857205] md: bind[ 7.857336] md: running: [ 7.857368] md: kicking non-fresh sdd1 from array! [ 7.857376] md: unbind [ 7.862026] md: export_rdev(sdd1) [ 7.890854] md: adding sdd2 ... [ 7.893244] md: bind [ 7.893365] md: running: [ 33.692736] md: bind [ 33.693189] md: kicking non-fresh sdd5 from array! [ 33.693209] md: unbind [ 33.696096] md: export_rdev(sdd5)
/proc/mdstat
The content of /proc/mdstat also confirms that /dev/sdd is not used for the main storage (md2) and md0 (DSM):
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4]
md2 : active raid5 sda5[0] sdc5[2] sdb5[1]
8776306368 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/3] [UUU_]
md1 : active raid1 sda2[0] sdb2[1] sdc2[2] sdd2[3]
2097088 blocks [16/4] [UUUU____________]
md0 : active raid1 sda1[0] sdb1[1] sdc1[3]
2490176 blocks [16/3] [UU_U____________]
As seen above, for md2 the last device is indicated as missing, and reading on the line above “md2 : active raid5 sda5[0] sdc5[2] sdb5[1]” list the order of the drives in “[UUU_]”, so this translates to [sda5 sdb5 sdc5 -]
The same goes for the md0 status where the order is different “md0 : active raid1 sda1[0] sdb1[1] sdc1[3]”, which translates to [sda1 sdb1 – sdc1]
smartctl output
I used smartctl to find out the drives mapped to /dev/sda[b-d]
root@DS918:~# smartctl --all /dev/sda smartctl 6.5 (build date May 7 2020) [x86_64-linux-4.4.59+] (local build) Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Vendor: HGST Product: HDN724030ALE640 ... Serial number: PK2238P3G3B8VJ
root@DS918:~# smartctl --all /dev/sdb smartctl 6.5 (build date May 7 2020) [x86_64-linux-4.4.59+] (local build) Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Vendor: HGST Product: HDN724030ALE640 ... Serial number: PK2234P9JGDEXY
root@DS918:~# smartctl --all /dev/sdc smartctl 6.5 (build date May 7 2020) [x86_64-linux-4.4.59+] (local build) Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Vendor: HGST Product: HDN724030ALE640 ... Serial number: PK2238P3G343GJ
root@DS918:~# smartctl --all /dev/sdd smartctl 6.5 (build date May 7 2020) [x86_64-linux-4.4.59+] (local build) Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Model Family: Seagate Barracuda 7200.14 (AF) Device Model: ST3000DM001-1ER166 Serial Number: W50090JM
As the fourth drive was a Seagate, it was easy to shut down the unit and check which drive it was, but with smartctl, you will be able to identify the drives by reading the serial number on its label.
The full smartctl output for the failed drive:
root@DS918:~# smartctl --all /dev/sdd
smartctl 6.5 (build date May 7 2020) [x86_64-linux-4.4.59+] (local build)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate Barracuda 7200.14 (AF)
Device Model: ST3000DM001-1ER166
Serial Number: W50090JM
LU WWN Device Id: 5 000c50 07c46d0aa
Firmware Version: CC43
User Capacity: 3,000,592,982,016 bytes [3.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 7200 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-2, ACS-3 T13/2161-D revision 3b
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Fri May 2 15:45:31 2025 CEST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x82) Offline data collection activity
was completed without error.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 113) The previous self-test completed having
the read element of the test failed.
Total time to complete Offline
data collection: ( 122) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 1) minutes.
Extended self-test routine
recommended polling time: ( 332) minutes.
Conveyance self-test routine
recommended polling time: ( 2) minutes.
SCT capabilities: (0x1085) SCT Status supported.
SMART Attributes Data Structure revision number: 10
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000f 086 084 006 Pre-fail Always - 221839714
3 Spin_Up_Time 0x0003 092 092 000 Pre-fail Always - 0
4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 84
5 Reallocated_Sector_Ct 0x0033 098 098 010 Pre-fail Always - 1968
7 Seek_Error_Rate 0x000f 090 060 030 Pre-fail Always - 998592914
9 Power_On_Hours 0x0032 051 051 000 Old_age Always - 43677
10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 34
183 Runtime_Bad_Block 0x0032 099 099 000 Old_age Always - 1
184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0
187 Reported_Uncorrect 0x0032 001 001 000 Old_age Always - 2714
188 Command_Timeout 0x0032 100 097 000 Old_age Always - 4 7 8
189 High_Fly_Writes 0x003a 099 099 000 Old_age Always - 1
190 Airflow_Temperature_Cel 0x0022 070 062 045 Old_age Always - 30 (Min/Max 27/38)
191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0
192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 8
193 Load_Cycle_Count 0x0032 065 065 000 Old_age Always - 70652
194 Temperature_Celsius 0x0022 030 040 000 Old_age Always - 30 (0 16 0 0 0)
197 Current_Pending_Sector 0x0012 001 001 000 Old_age Always - 49760
198 Offline_Uncorrectable 0x0010 001 001 000 Old_age Offline - 49760
199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 38460h+46m+12.675s
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 15195564747
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 1092464909408
SMART Error Log Version: 1
ATA Error Count: 2713 (device log contains only the most recent five errors)
CR = Command Register [HEX]
FR = Features Register [HEX]
SC = Sector Count Register [HEX]
SN = Sector Number Register [HEX]
CL = Cylinder Low Register [HEX]
CH = Cylinder High Register [HEX]
DH = Device/Head Register [HEX]
DC = Device Command Register [HEX]
ER = Error register [HEX]
ST = Status register [HEX]
Powered_Up_Time is measured from power on, and printed as
DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes,
SS=sec, and sss=millisec. It "wraps" after 49.710 days.
Error 2713 occurred at disk power-on lifetime: 32907 hours (1371 days + 3 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 53 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 00 08 ff ff ff 4f 00 33d+13:49:54.056 READ FPDMA QUEUED
ef 10 02 00 00 00 a0 00 33d+13:49:54.048 SET FEATURES [Enable SATA feature]
27 00 00 00 00 00 e0 00 33d+13:49:54.048 READ NATIVE MAX ADDRESS EXT [OBS-ACS-3]
ec 00 00 00 00 00 a0 00 33d+13:49:54.047 IDENTIFY DEVICE
ef 03 46 00 00 00 a0 00 33d+13:49:54.047 SET FEATURES [Set transfer mode]
Error 2712 occurred at disk power-on lifetime: 32907 hours (1371 days + 3 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 53 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 00 08 ff ff ff 4f 00 33d+13:49:49.959 READ FPDMA QUEUED
60 00 08 ff ff ff 4f 00 33d+13:49:49.958 READ FPDMA QUEUED
ef 10 02 00 00 00 a0 00 33d+13:49:49.949 SET FEATURES [Enable SATA feature]
27 00 00 00 00 00 e0 00 33d+13:49:49.949 READ NATIVE MAX ADDRESS EXT [OBS-ACS-3]
ec 00 00 00 00 00 a0 00 33d+13:49:49.949 IDENTIFY DEVICE
Error 2711 occurred at disk power-on lifetime: 32907 hours (1371 days + 3 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 53 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 00 08 ff ff ff 4f 00 33d+13:49:46.267 READ FPDMA QUEUED
60 00 08 ff ff ff 4f 00 33d+13:49:46.267 READ FPDMA QUEUED
60 00 08 ff ff ff 4f 00 33d+13:49:46.267 READ FPDMA QUEUED
60 00 08 ff ff ff 4f 00 33d+13:49:46.266 READ FPDMA QUEUED
ef 10 02 00 00 00 a0 00 33d+13:49:46.258 SET FEATURES [Enable SATA feature]
Error 2710 occurred at disk power-on lifetime: 32907 hours (1371 days + 3 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 53 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 00 08 ff ff ff 4f 00 33d+13:49:41.370 READ FPDMA QUEUED
60 00 08 ff ff ff 4f 00 33d+13:49:41.370 READ FPDMA QUEUED
60 00 08 ff ff ff 4f 00 33d+13:49:41.370 READ FPDMA QUEUED
60 00 08 ff ff ff 4f 00 33d+13:49:41.370 READ FPDMA QUEUED
60 00 08 ff ff ff 4f 00 33d+13:49:41.369 READ FPDMA QUEUED
Error 2709 occurred at disk power-on lifetime: 32907 hours (1371 days + 3 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
40 53 00 ff ff ff 0f Error: UNC at LBA = 0x0fffffff = 268435455
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 00 08 ff ff ff 4f 00 33d+13:49:36.656 READ FPDMA QUEUED
60 00 08 ff ff ff 4f 00 33d+13:49:36.656 READ FPDMA QUEUED
60 00 08 ff ff ff 4f 00 33d+13:49:36.656 READ FPDMA QUEUED
60 00 08 ff ff ff 4f 00 33d+13:49:36.656 READ FPDMA QUEUED
60 00 08 ff ff ff 4f 00 33d+13:49:36.656 READ FPDMA QUEUED
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed: read failure 10% 43133 4084368632
# 2 Short offline Completed: read failure 10% 42391 4084368632
# 3 Short offline Completed: read failure 40% 41719 4084368632
# 4 Short offline Completed: read failure 10% 40975 4084368632
# 5 Short offline Completed: read failure 80% 40231 4084368632
# 6 Short offline Completed: read failure 10% 39511 4084368632
# 7 Short offline Completed: read failure 10% 38766 4084368632
# 8 Short offline Completed: read failure 10% 32938 4084368632
# 9 Short offline Completed without error 00% 32193 -
#10 Short offline Completed without error 00% 31449 -
#11 Short offline Completed without error 00% 30743 -
#12 Short offline Completed without error 00% 29998 -
#13 Short offline Completed without error 00% 29278 -
#14 Short offline Completed without error 00% 28534 -
#15 Short offline Completed without error 00% 27790 -
#16 Short offline Completed without error 00% 27070 -
#17 Short offline Completed without error 00% 26328 -
#18 Short offline Completed without error 00% 25608 -
#19 Short offline Completed without error 00% 24865 -
#20 Short offline Completed without error 00% 24196 -
#21 Short offline Completed without error 00% 23452 -
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.
I powered down the unit (using DSM ui) and identified and removed the broken drive. Then I started it up again (the replacement drive was not inserted). When the replacement drive was inserted DSM didn’t immediately see it, so I just did a reboot of the unit to make it appear as an unused drive, then selecting “Repair” from “Storage Manager/Storage Pool”.
The rebuilding process – first drive
I monitored the rebuilding process a few times, but did not take any notes of when (how long it took). Just let it finish during the night:
root@DS918:~# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4]
md2 : active raid5 sdd5[4] sda5[0] sdc5[2] sdb5[1]
8776306368 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/3] [UUU_]
[>....................] recovery = 0.5% (15458048/2925435456) finish=534.6min speed=90708K/sec
md1 : active raid1 sdd2[3] sdc2[2] sdb2[1] sda2[0]
2097088 blocks [16/4] [UUUU____________]
md0 : active raid1 sdd1[2] sda1[0] sdb1[1] sdc1[3]
2490176 blocks [16/4] [UUUU____________]
unused devices:
root@DS918:~# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4]
md2 : active raid5 sdd5[4] sda5[0] sdc5[2] sdb5[1]
8776306368 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/3] [UUU_]
[=>...................] recovery = 9.6% (282353128/2925435456) finish=434.7min speed=101335K/sec
md1 : active raid1 sdd2[3] sdc2[2] sdb2[1] sda2[0]
2097088 blocks [16/4] [UUUU____________]
md0 : active raid1 sdd1[2] sda1[0] sdb1[1] sdc1[3]
2490176 blocks [16/4] [UUUU____________]
unused devices:
root@DS918:~# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4]
md2 : active raid5 sdd5[4] sda5[0] sdc5[2] sdb5[1]
8776306368 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/3] [UUU_]
[=======>.............] recovery = 38.2% (1118697376/2925435456) finish=525.1min speed=57343K/sec
md1 : active raid1 sdd2[3] sdc2[2] sdb2[1] sda2[0]
2097088 blocks [16/4] [UUUU____________]
md0 : active raid1 sdd1[2] sda1[0] sdb1[1] sdc1[3]
2490176 blocks [16/4] [UUUU____________]
unused devices:
root@DS918:~# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4]
md2 : active raid5 sdd5[4] sda5[0] sdc5[2] sdb5[1]
8776306368 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/3] [UUU_]
[=======>.............] recovery = 39.4% (1152686672/2925435456) finish=402.3min speed=73435K/sec
md1 : active raid1 sdd2[3] sdc2[2] sdb2[1] sda2[0]
2097088 blocks [16/4] [UUUU____________]
md0 : active raid1 sdd1[2] sda1[0] sdb1[1] sdc1[3]
2490176 blocks [16/4] [UUUU____________]
unused devices:
root@DS918:~# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4]
md2 : active raid5 sdd5[4] sda5[0] sdc5[2] sdb5[1]
8776306368 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/3] [UUU_]
[=========>...........] recovery = 49.3% (1443636996/2925435456) finish=297.2min speed=83074K/sec
md1 : active raid1 sdd2[3] sdc2[2] sdb2[1] sda2[0]
2097088 blocks [16/4] [UUUU____________]
md0 : active raid1 sdd1[2] sda1[0] sdb1[1] sdc1[3]
2490176 blocks [16/4] [UUUU____________]
unused devices:
root@DS918:~# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4]
md2 : active raid5 sdd5[4] sda5[0] sdc5[2] sdb5[1]
8776306368 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/4] [UUUU]
md1 : active raid1 sdd2[3] sdc2[2] sdb2[1] sda2[0]
2097088 blocks [16/4] [UUUU____________]
md0 : active raid1 sdd1[2] sda1[0] sdb1[1] sdc1[3]
2490176 blocks [16/4] [UUUU____________]
unused devices:
Partition layout before and after first disk swap
With the broken disk removed, the partition layout of the remaining disks looked like this:
root@DS918:~# sfdisk -l /dev/sda1 2048 4982527 4980480 fd /dev/sda2 4982528 9176831 4194304 fd /dev/sda5 9453280 5860326239 5850872960 fd /dev/sdb1 2048 4982527 4980480 fd /dev/sdb2 4982528 9176831 4194304 fd /dev/sdb5 9453280 5860326239 5850872960 fd /dev/sdc1 2048 4982527 4980480 fd /dev/sdc2 4982528 9176831 4194304 fd /dev/sdc5 9453280 5860326239 5850872960 fd
When the rebuild process had started, the new disk (/dev/sdd) got the same partition layout as the others, but also a partition for the remaining space (for now unused/unusable)
root@DS918:~# sfdisk -l /dev/sda1 2048 4982527 4980480 fd /dev/sda2 4982528 9176831 4194304 fd /dev/sda5 9453280 5860326239 5850872960 fd /dev/sdb1 2048 4982527 4980480 fd /dev/sdb2 4982528 9176831 4194304 fd /dev/sdb5 9453280 5860326239 5850872960 fd /dev/sdc1 2048 4982527 4980480 fd /dev/sdc2 4982528 9176831 4194304 fd /dev/sdc5 9453280 5860326239 5850872960 fd /dev/sdd1 2048 4982527 4980480 fd /dev/sdd2 4982528 9176831 4194304 fd /dev/sdd5 9453280 5860326239 5850872960 fd /dev/sdd6 5860342336 15627846239 9767503904 fd
Second disk pulled out
Now that the first disk had been replaced and the raid was rebuild, I just pulled out the second one to replace.
root@DS918:~# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4]
md2 : active raid5 sdd5[4] sda5[0] sdb5[1]
8776306368 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/3] [UU_U]
md1 : active raid1 sdd2[3] sdb2[1] sda2[0]
2097088 blocks [16/3] [UU_U____________]
md0 : active raid1 sdd1[2] sda1[0] sdb1[1]
2490176 blocks [16/3] [UUU_____________]
unused devices:
When I inserted the replacement disk, it was (this time) detected by the unit (since the drive was already known before pulling it).
[53977.141054] ata3: link reset sucessfully clear error flags [53977.157449] ata3.00: ATA-9: ST8000AS0002-1NA17Z, AR17, max UDMA/133 [53977.157458] ata3.00: 15628053168 sectors, multi 0: LBA48 NCQ (depth 31/32), AA [53977.157462] ata3.00: SN: Z841474Z [53977.158764] ata3.00: configured for UDMA/133 [53977.158779] ata3.00: Write Cache is enabled [53977.163030] ata3: EH complete [53977.164533] scsi 2:0:0:0: Direct-Access ATA ST8000AS0002-1NA17Z AR17 PQ: 0 ANSI: 5 [53977.165256] sd 2:0:0:0: [sdc] 15628053168 512-byte logical blocks: (8.00 TB/7.28 TiB) [53977.165273] sd 2:0:0:0: [sdc] 4096-byte physical blocks [53977.165298] sd 2:0:0:0: Attached scsi generic sg2 type 0 [53977.165534] sd 2:0:0:0: [sdc] Write Protect is off [53977.165547] sd 2:0:0:0: [sdc] Mode Sense: 00 3a 00 00 [53977.165662] sd 2:0:0:0: [sdc] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA [53977.217123] sdc: sdc1 sdc2 [53977.218062] sd 2:0:0:0: [sdc] Attached SCSI disk
Full content from dmesg output since starting the unit. This shows that the rebuild time of md2 was about 10 hours, more or less as expected when it was started (early output of /proc/mdstat).
[ 323.429093] perf interrupt took too long (5018 > 5000), lowering kernel.perf_event_max_sample_rate to 25000
[36561.042407] md: md2: recovery done.
[36561.200565] md: md2: set sdd5 to auto_remap [0]
[36561.200576] md: md2: set sda5 to auto_remap [0]
[36561.200581] md: md2: set sdc5 to auto_remap [0]
[36561.200585] md: md2: set sdb5 to auto_remap [0]
[36561.405942] RAID conf printout:
[36561.405954] --- level:5 rd:4 wd:4
[36561.405959] disk 0, o:1, dev:sda5
[36561.405963] disk 1, o:1, dev:sdb5
[36561.405967] disk 2, o:1, dev:sdc5
[36561.405971] disk 3, o:1, dev:sdd5
[53370.783902] ata3: device unplugged sstatus 0x0
[53370.783962] ata3: exception Emask 0x10 SAct 0x0 SErr 0x4010000 action 0xe frozen
[53370.791503] ata3: irq_stat 0x00400040, connection status changed
[53370.797628] ata3: SError: { PHYRdyChg DevExch }
[53370.802258] ata3: hard resetting link
[53371.525046] ata3: SATA link down (SStatus 0 SControl 300)
[53371.525054] ata3: No present pin info for SATA link down event
[53373.531047] ata3: hard resetting link
[53373.836045] ata3: SATA link down (SStatus 0 SControl 300)
[53373.836054] ata3: No present pin info for SATA link down event
[53373.841917] ata3: limiting SATA link speed to 1.5 Gbps
[53375.841041] ata3: hard resetting link
[53376.146048] ata3: SATA link down (SStatus 0 SControl 310)
[53376.146056] ata3: No present pin info for SATA link down event
[53376.151920] ata3.00: disabled
[53376.151928] ata3.00: already disabled (class=0x2)
[53376.151933] ata3.00: already disabled (class=0x2)
[53376.151958] ata3: EH complete
[53376.151980] ata3.00: detaching (SCSI 2:0:0:0)
[53376.152704] sd 2:0:0:0: [sdc] tag#21 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=0x00
[53376.152717] sd 2:0:0:0: [sdc] tag#21 CDB: opcode=0x35 35 00 00 00 00 00 00 00 00 00
[53376.152730] blk_update_request: I/O error, dev sdc, sector in range 4980736 + 0-2(12)
[53376.153061] md: super_written gets error=-5
[53376.153061] syno_md_error: sdc1 has been removed
[53376.153061] raid1: Disk failure on sdc1, disabling device.
Operation continuing on 3 devices
[53376.177112] sd 2:0:0:0: [sdc] Synchronizing SCSI cache
[53376.177232] sd 2:0:0:0: [sdc] Synchronize Cache(10) failed: Result: hostbyte=0x04 driverbyte=0x00
[53376.177238] sd 2:0:0:0: [sdc] Stopping disk
[53376.177269] sd 2:0:0:0: [sdc] Start/Stop Unit failed: Result: hostbyte=0x04 driverbyte=0x00
[53376.183106] RAID1 conf printout:
[53376.183118] --- wd:3 rd:16
[53376.183125] disk 0, wo:0, o:1, dev:sda1
[53376.183130] disk 1, wo:0, o:1, dev:sdb1
[53376.183135] disk 2, wo:0, o:1, dev:sdd1
[53376.183140] disk 3, wo:1, o:0, dev:sdc1
[53376.184338] SynoCheckRdevIsWorking (11054): remove active disk sdc5 from md2 raid_disks 4 mddev->degraded 0 mddev->level 5
[53376.184376] syno_md_error: sdc5 has been removed
[53376.184387] md/raid:md2: Disk failure on sdc5, disabling device.
md/raid:md2: Operation continuing on 3 devices.
[53376.196472] SynoCheckRdevIsWorking (11054): remove active disk sdc2 from md1 raid_disks 16 mddev->degraded 12 mddev->level 1
[53376.196491] syno_md_error: sdc2 has been removed
[53376.196497] raid1: Disk failure on sdc2, disabling device.
Operation continuing on 3 devices
[53376.198033] RAID1 conf printout:
[53376.198035] --- wd:3 rd:16
[53376.198038] disk 0, wo:0, o:1, dev:sda1
[53376.198040] disk 1, wo:0, o:1, dev:sdb1
[53376.198042] disk 2, wo:0, o:1, dev:sdd1
[53376.206669] syno_hot_remove_disk (10954): cannot remove active disk sdc2 from md1 ... rdev->raid_disk 2 pending 0
[53376.330347] md: ioctl lock interrupted, reason -4, cmd -2145908384
[53376.446860] RAID conf printout:
[53376.446869] --- level:5 rd:4 wd:3
[53376.446874] disk 0, o:1, dev:sda5
[53376.446879] disk 1, o:1, dev:sdb5
[53376.446883] disk 2, o:0, dev:sdc5
[53376.446886] disk 3, o:1, dev:sdd5
[53376.454062] RAID conf printout:
[53376.454072] --- level:5 rd:4 wd:3
[53376.454077] disk 0, o:1, dev:sda5
[53376.454082] disk 1, o:1, dev:sdb5
[53376.454086] disk 3, o:1, dev:sdd5
[53376.460958] SynoCheckRdevIsWorking (11054): remove active disk sdc1 from md0 raid_disks 16 mddev->degraded 13 mddev->level 1
[53376.460968] RAID1 conf printout:
[53376.460972] --- wd:3 rd:16
[53376.460978] disk 0, wo:0, o:1, dev:sda2
[53376.460984] disk 1, wo:0, o:1, dev:sdb2
[53376.460987] md: unbind
[53376.460992] disk 2, wo:1, o:0, dev:sdc2
[53376.460998] disk 3, wo:0, o:1, dev:sdd2
[53376.467047] RAID1 conf printout:
[53376.467056] --- wd:3 rd:16
[53376.467062] disk 0, wo:0, o:1, dev:sda2
[53376.467066] disk 1, wo:0, o:1, dev:sdb2
[53376.467070] disk 3, wo:0, o:1, dev:sdd2
[53376.470067] md: export_rdev(sdc1)
[53376.475613] md: unbind
[53376.480044] md: export_rdev(sdc5)
[53377.207047] SynoCheckRdevIsWorking (11054): remove active disk sdc2 from md1 raid_disks 16 mddev->degraded 13 mddev->level 1
[53377.207072] md: unbind
[53377.212034] md: export_rdev(sdc2)
[53958.581765] ata3: device plugged sstatus 0x1
[53958.581811] ata3: exception Emask 0x10 SAct 0x0 SErr 0x4000000 action 0xe frozen
[53958.589278] ata3: irq_stat 0x00000040, connection status changed
[53958.595322] ata3: SError: { DevExch }
[53958.599069] ata3: hard resetting link
[53964.371031] ata3: link is slow to respond, please be patient (ready=0)
[53968.757039] ata3: softreset failed (device not ready)
[53968.762111] ata3: SRST fail, set srst fail flag
[53968.766667] ata3: hard resetting link
[53974.538032] ata3: link is slow to respond, please be patient (ready=0)
[53977.141041] ata3: SATA link up 3.0 Gbps (SStatus 123 SControl 300)
[53977.141054] ata3: link reset sucessfully clear error flags
[53977.157449] ata3.00: ATA-9: ST8000AS0002-1NA17Z, AR17, max UDMA/133
[53977.157458] ata3.00: 15628053168 sectors, multi 0: LBA48 NCQ (depth 31/32), AA
[53977.157462] ata3.00: SN: Z841474Z
[53977.158764] ata3.00: configured for UDMA/133
[53977.158779] ata3.00: Write Cache is enabled
[53977.163030] ata3: EH complete
[53977.164533] scsi 2:0:0:0: Direct-Access ATA ST8000AS0002-1NA17Z AR17 PQ: 0 ANSI: 5
[53977.165256] sd 2:0:0:0: [sdc] 15628053168 512-byte logical blocks: (8.00 TB/7.28 TiB)
[53977.165273] sd 2:0:0:0: [sdc] 4096-byte physical blocks
[53977.165298] sd 2:0:0:0: Attached scsi generic sg2 type 0
[53977.165534] sd 2:0:0:0: [sdc] Write Protect is off
[53977.165547] sd 2:0:0:0: [sdc] Mode Sense: 00 3a 00 00
[53977.165662] sd 2:0:0:0: [sdc] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA
[53977.217123] sdc: sdc1 sdc2
[53977.218062] sd 2:0:0:0: [sdc] Attached SCSI disk
Even when the new drive had been detected, I rebooted the unit “just to be sure”, then I initiated the repair process from DSM again. After letting it run for a while, I checked the status:
root@DS918:~# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4]
md2 : active raid5 sdc5[5] sda5[0] sdd5[4] sdb5[1]
8776306368 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/3] [UU_U]
[=>...................] recovery = 9.1% (266365608/2925435456) finish=564.1min speed=78549K/sec
md1 : active raid1 sdc2[3] sdd2[2] sdb2[1] sda2[0]
2097088 blocks [16/4] [UUUU____________]
md0 : active raid1 sdc1[3] sda1[0] sdb1[1] sdd1[2]
2490176 blocks [16/4] [UUUU____________]
unused devices:
Partition layout after the second disk swap
After changing the second drive (/dev/sdc) and starting the rebuild process, the new disk got the same partition layout as the first replaced one (/dev/sdd):
root@DS918:~# sfdisk -l /dev/sda1 2048 4982527 4980480 fd /dev/sda2 4982528 9176831 4194304 fd /dev/sda5 9453280 5860326239 5850872960 fd /dev/sdb1 2048 4982527 4980480 fd /dev/sdb2 4982528 9176831 4194304 fd /dev/sdb5 9453280 5860326239 5850872960 fd /dev/sdc1 2048 4982527 4980480 fd /dev/sdc2 4982528 9176831 4194304 fd /dev/sdc5 9453280 5860326239 5850872960 fd /dev/sdc6 5860342336 15627846239 9767503904 fd /dev/sdd1 2048 4982527 4980480 fd /dev/sdd2 4982528 9176831 4194304 fd /dev/sdd5 9453280 5860326239 5850872960 fd /dev/sdd6 5860342336 15627846239 9767503904 fd
The rebuild will again take about 10 hours to finish.
What’s expected to happen next
Because there are now two partitions with unused space on the new drives, the md2 volume will be rebuilt as RAID5 on sd[a-d]5 + the additional space of RAID1 on sdc6 and sdd6. There seems no way of stopping this stupidity, since it will have to be redone again after swapping the next disk. Just sit back and wait for the expansion of the mdraid volume.
Unless…
It might be a time saver to delete the unused partition on the first disk, so that the storage cannot be expanded (what happens will depend on if DSM notices the non-partitioned space and still makes that mirror of sdd6 + sdc6)
There’s only one way to find out:
root@DS918:~# parted /dev/sdd GNU Parted 3.2 Using /dev/sdd Welcome to GNU Parted! Type 'help' to view a list of commands. (parted) rm 6 rm 6 (parted) print print Model: ATA ST8000AS0002-1NA (scsi) Disk /dev/sdd: 8002GB Sector size (logical/physical): 512B/512B Partition Table: gpt Disk Flags: Number Start End Size File system Name Flags 1 1049kB 2551MB 2550MB ext4 raid 2 2551MB 4699MB 2147MB linux-swap(v1) raid 5 4840MB 3000GB 2996GB raid (parted) quit
10 hours later…
At right about 10 hours later, md2 was almost rebuilt. No problems so far, but what follows will be interesting as I removed that extra partition (which would have been a part of the LV used for storage). I really hope that the NAS would be ready to accept the next disk in the replacemend procedure right after the sync is finished.
root@DS918:~# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4]
md2 : active raid5 sdc5[5] sda5[0] sdd5[4] sdb5[1]
8776306368 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/3] [UU_U]
[==================>..] recovery = 94.4% (2763366352/2925435456) finish=35.3min speed=76346K/sec
md1 : active raid1 sdc2[3] sdd2[2] sdb2[1] sda2[0]
2097088 blocks [16/4] [UUUU____________]
md0 : active raid1 sdc1[3] sda1[0] sdb1[1] sdd1[2]
2490176 blocks [16/4] [UUUU____________]
unused devices:
Results after the second disk swap
As hoped for, no automatic LV change was initiated, saving me a lot of hours (at least, for now) skipping the reshape operation which would then have to be done at least one time after swapping out the remaining disks.
root@DS918:~# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4]
md2 : active raid5 sdc5[5] sda5[0] sdd5[4] sdb5[1]
8776306368 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/4] [UUUU]
md1 : active raid1 sdc2[3] sdd2[2] sdb2[1] sda2[0]
2097088 blocks [16/4] [UUUU____________]
md0 : active raid1 sdc1[3] sda1[0] sdb1[1] sdd1[2]
2490176 blocks [16/4] [UUUU____________]
unused devices:
Partitions on /dev/sdc at this stage:
root@DS918:~# sfdisk -l /dev/sda1 2048 4982527 4980480 fd /dev/sda2 4982528 9176831 4194304 fd /dev/sda5 9453280 5860326239 5850872960 fd /dev/sdb1 2048 4982527 4980480 fd /dev/sdb2 4982528 9176831 4194304 fd /dev/sdb5 9453280 5860326239 5850872960 fd /dev/sdc1 2048 4982527 4980480 fd /dev/sdc2 4982528 9176831 4194304 fd /dev/sdc5 9453280 5860326239 5850872960 fd /dev/sdc6 5860342336 15627846239 9767503904 fd /dev/sdd1 2048 4982527 4980480 fd /dev/sdd2 4982528 9176831 4194304 fd /dev/sdd5 9453280 5860326239 5850872960 fd
Replacing the third disk
I’m doing it exactly the same way as when I replaced the second disk:
Pull out the drive
Replace and check
Reboot just to be sure
Rebuild
Remove the extra partition on sdc to prevent reshaping after rebuild
After the 3rd disk change had been accepted (to be resynced), I got some unexpected things happening. Even with the removed partition on sdc, DSM decided that it could make partition changes to make the most use of the disks available:
root@DS918:~# sfdisk -l /dev/sda1 2048 4982527 4980480 fd /dev/sda2 4982528 9176831 4194304 fd /dev/sda5 9453280 5860326239 5850872960 fd /dev/sdb1 2048 4982527 4980480 fd /dev/sdb2 4982528 9176831 4194304 fd /dev/sdb5 9453280 5860326239 5850872960 fd /dev/sdb6 5860342336 15627846239 9767503904 fd /dev/sdc1 2048 4982527 4980480 fd /dev/sdc2 4982528 9176831 4194304 fd /dev/sdc5 9453280 5860326239 5850872960 fd /dev/sdc6 5860342336 15627846239 9767503904 fd /dev/sdd1 2048 4982527 4980480 fd /dev/sdd2 4982528 9176831 4194304 fd /dev/sdd5 9453280 5860326239 5850872960 fd /dev/sdd6 5860342336 15627846239 9767503904 fd
The removed partition from sdd was recreated, and now sdb6, sdc6 and sdd6 will be a RAID5 which will be striped onto the storage LV. Not what I hoped for, but probably nothing that could have been done to prevent it from happening (I think all three extra partitions would have been created even if I removed the one from sdc).
Checking the mdraid status, I noticed that there might be some hope (again, by removing the extra partition on each of the disks that have been completely replaced):
root@DS918:~# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4]
md2 : active raid5 sdb5[6] sda5[0] sdd5[4] sdc5[5]
8776306368 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/3] [U_UU]
[=>...................] recovery = 8.5% (249970824/2925435456) finish=696.8min speed=63988K/sec
md1 : active raid1 sdb2[3] sdd2[2] sdc2[1] sda2[0]
2097088 blocks [16/4] [UUUU____________]
md0 : active raid1 sdb1[1] sda1[0] sdc1[3] sdd1[2]
2490176 blocks [16/4] [UUUU____________]
unused devices:
As the new partitions are not in use yet, I just remove them from the disks (sdc and sdd) using parted.
After removing these partitions, the disks looks like I want them for now:
root@DS918:~# sfdisk -l /dev/sda1 2048 4982527 4980480 fd /dev/sda2 4982528 9176831 4194304 fd /dev/sda5 9453280 5860326239 5850872960 fd /dev/sdb1 2048 4982527 4980480 fd /dev/sdb2 4982528 9176831 4194304 fd /dev/sdb5 9453280 5860326239 5850872960 fd /dev/sdb6 5860342336 15627846239 9767503904 fd /dev/sdc1 2048 4982527 4980480 fd /dev/sdc2 4982528 9176831 4194304 fd /dev/sdc5 9453280 5860326239 5850872960 fd /dev/sdd1 2048 4982527 4980480 fd /dev/sdd2 4982528 9176831 4194304 fd /dev/sdd5 9453280 5860326239 5850872960 fd
On the next disk replacement (the last), I will let it expand the storage pool to use the free space from the new disks (as they are 8TB each and the old ones were 3TB, this will add 15TB to the volume).
Snapshots from DSM web UI
The first snapshot of the UI was done after replacing the third disk when something unexpected happened, but I include the story up to that point for those few interested in reading my stuff 🙂
These snapshots (taken while disk 3 is being rebuilt) are still a vaild representation for how the unit was configured before changing (disk 4, 3 and 2, as I began from the bottom with the broken one).
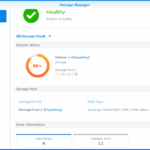
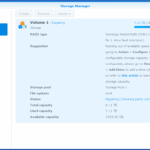
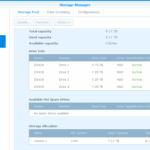
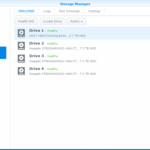
I began with a total volume of 8TB, which I replaced the failing drive with a new 8TB. This made the volume size unchangeable (because redundancy cannot be done with the help of only that 5TB unused space on the new drive).
When changing the second drive, DSM told me the new size of the would be about 12TB, which is the old 8TB (RAID5 across the four disks) + the 5GB free space from the new drives (partition 6 mirrored). This was not what I wanted, so I deleted partition 6 from one of the drives, and that worked, preventing the storage pool from being expanded.
Replacing the third disk (as I have detailed just above) made the assumption that I really wanted to use the free space from the two other drives + the third of the same kind (even with the extra partition removed from sdc). This time I got noticed that the storage pool will grow to about 17TB. Still not what I wanted, and after checking that nothing had been changed, I went on removing the 5TB partitions from sdc and sdd.
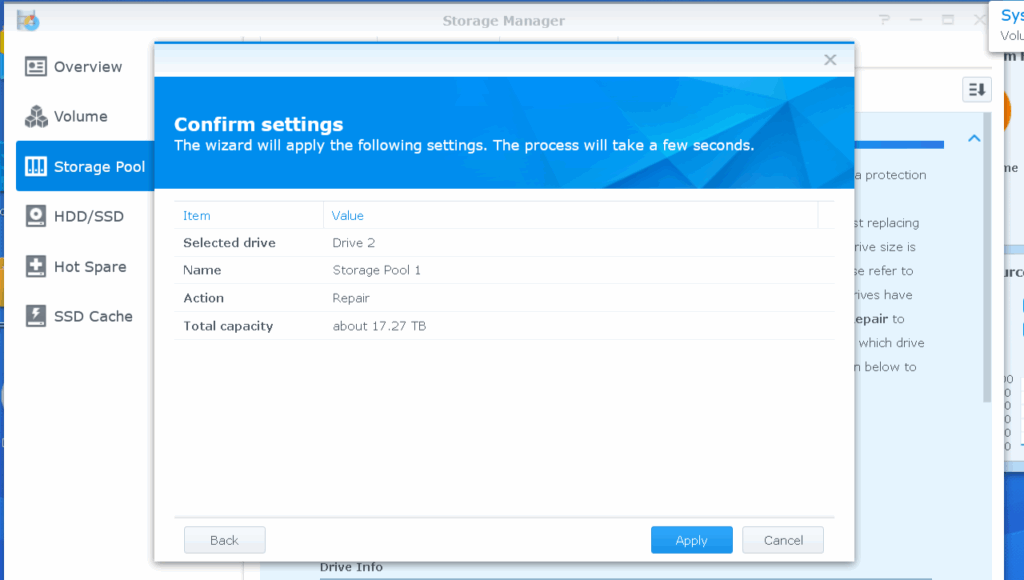
11,7 hours later…
Storage pool untouched.
root@DS918:~# cat /etc/lvm/backup/vg1
# Generated by LVM2 version 2.02.132(2)-git (2015-09-22): Sat May 3 05:20:41 2025
contents = "Text Format Volume Group"
version = 1
description = "Created *after* executing '/sbin/pvresize /dev/md2'"
creation_host = "DS918" # Linux DS918 4.4.59+ #25426 SMP PREEMPT Mon Dec 14 18:48:50 CST 2020 x86_64
creation_time = 1746242441 # Sat May 3 05:20:41 2025
vg1 {
id = "jkiRc4-0zwx-ye9v-1eFm-OL0u-7oSS-x51FA8"
seqno = 4
format = "lvm2" # informational
status = ["RESIZEABLE", "READ", "WRITE"]
flags = []
extent_size = 8192 # 4 Megabytes
max_lv = 0
max_pv = 0
metadata_copies = 0
physical_volumes {
pv0 {
id = "yu1P7E-7o1a-8CsP-mbaR-mye5-N4pk-1fAk8O"
device = "/dev/md2" # Hint only
status = ["ALLOCATABLE"]
flags = []
dev_size = 17552611584 # 8.17357 Terabytes
pe_start = 1152
pe_count = 2142652 # 8.17357 Terabytes
}
}
logical_volumes {
syno_vg_reserved_area {
id = "3YdjJW-zkx6-DoKs-jEz0-kTXo-rpke-eYIw8P"
status = ["READ", "WRITE", "VISIBLE"]
flags = []
segment_count = 1
segment1 {
start_extent = 0
extent_count = 3 # 12 Megabytes
type = "striped"
stripe_count = 1 # linear
stripes = [
"pv0", 0
]
}
}
volume_1 {
id = "BFxwgA-3pr2-3BHr-AXo3-rJ6r-F7tP-vC7Te7"
status = ["READ", "WRITE", "VISIBLE"]
flags = []
segment_count = 1
segment1 {
start_extent = 0
extent_count = 2142649 # 8.17356 Terabytes
type = "striped"
stripe_count = 1 # linear
stripes = [
"pv0", 3
]
}
}
}
}
mdraid volumes untouched:
root@DS918:~# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4]
md2 : active raid5 sdb5[6] sda5[0] sdd5[4] sdc5[5]
8776306368 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/4] [UUUU]
md1 : active raid1 sdb2[3] sdd2[2] sdc2[1] sda2[0]
2097088 blocks [16/4] [UUUU____________]
md0 : active raid1 sdb1[1] sda1[0] sdc1[3] sdd1[2]
2490176 blocks [16/4] [UUUU____________]
unused devices:
LV also untouched, just as I wanted.
root@DS918:~# lvdisplay --- Logical volume --- LV Path /dev/vg1/syno_vg_reserved_area LV Name syno_vg_reserved_area VG Name vg1 LV UUID 3YdjJW-zkx6-DoKs-jEz0-kTXo-rpke-eYIw8P LV Write Access read/write LV Creation host, time , LV Status available # open 0 LV Size 12.00 MiB Current LE 3 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 768 Block device 252:0 --- Logical volume --- LV Path /dev/vg1/volume_1 LV Name volume_1 VG Name vg1 LV UUID BFxwgA-3pr2-3BHr-AXo3-rJ6r-F7tP-vC7Te7 LV Write Access read/write LV Creation host, time , LV Status available # open 1 LV Size 8.17 TiB Current LE 2142649 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 4096 Block device 252:1
Replacing the last drive
I follow the same procedure as with the other ones, with one exception: I let the Synology do its magic and expand the storage pool by leaving the 5GB partitions on the drives.
Pull out the drive
Replace and check
Reboot just to be sure
Rebuild
Let the Synology expand the storage pool
After the reboot, I just did a “Repair” on the pool again, and confirmed that the new size will be about 21TB (old size of 8TB + RAID5 on four 5TB partitions giving the 15TB extra space):
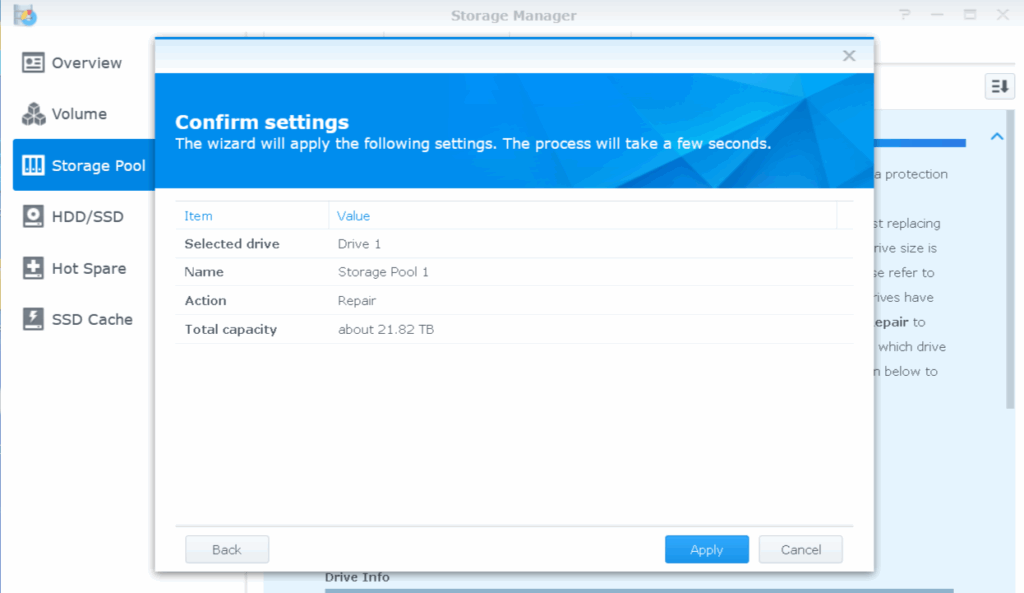
Partition layout on the disks after starting the rebuild:
root@DS918:~# sfdisk -l /dev/sda1 2048 4982527 4980480 fd /dev/sda2 4982528 9176831 4194304 fd /dev/sda5 9453280 5860326239 5850872960 fd /dev/sda6 5860342336 15627846239 9767503904 fd /dev/sdb1 2048 4982527 4980480 fd /dev/sdb2 4982528 9176831 4194304 fd /dev/sdb5 9453280 5860326239 5850872960 fd /dev/sdb6 5860342336 15627846239 9767503904 fd /dev/sdc1 2048 4982527 4980480 fd /dev/sdc2 4982528 9176831 4194304 fd /dev/sdc5 9453280 5860326239 5850872960 fd /dev/sdc6 5860342336 15627846239 9767503904 fd /dev/sdd1 2048 4982527 4980480 fd /dev/sdd2 4982528 9176831 4194304 fd /dev/sdd5 9453280 5860326239 5850872960 fd /dev/sdd6 5860342336 15627846239 9767503904 fd
Now I just have to wait…
Something unexpected happened
After that reboot (before initiating rebuild), “md2” for some reason changed to “md4”. The reason for this could be that “md2” and “md3” were unavailable because the last disk came from a FreeBSD:ed older Buffalo, so mdraid detected this and reassigned “md2” as “md4”.
For reference only, the partition tables just after inserting the disk that now should be the new and last replacement:
root@DS918:~# sfdisk -l /dev/sda1 2048 2002943 2000896 83 /dev/sda2 2002944 12003327 10000384 83 /dev/sda3 12003328 12005375 2048 83 /dev/sda4 12005376 12007423 2048 83 /dev/sda5 12007424 14008319 2000896 83 /dev/sda6 14008320 7814008319 7800000000 83 /dev/sda7 7814008832 15614008831 7800000000 83 /dev/sdb1 2048 4982527 4980480 fd /dev/sdb2 4982528 9176831 4194304 fd /dev/sdb5 9453280 5860326239 5850872960 fd /dev/sdb6 5860342336 15627846239 9767503904 fd /dev/sdc1 2048 4982527 4980480 fd /dev/sdc2 4982528 9176831 4194304 fd /dev/sdc5 9453280 5860326239 5850872960 fd /dev/sdd1 2048 4982527 4980480 fd /dev/sdd2 4982528 9176831 4194304 fd /dev/sdd5 9453280 5860326239 5850872960 fd
So at least until the next reboot, the output from /proc/mdstat would look like this:
root@DS918:~# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4]
md4 : active raid5 sda5[7] sdb5[6] sdd5[4] sdc5[5]
8776306368 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/3] [_UUU]
[==============>......] recovery = 73.4% (2148539264/2925435456) finish=112.3min speed=115278K/sec
md1 : active raid1 sda2[3] sdd2[2] sdc2[1] sdb2[0]
2097088 blocks [16/4] [UUUU____________]
md0 : active raid1 sda1[0] sdb1[1] sdc1[3] sdd1[2]
2490176 blocks [16/4] [UUUU____________]
unused devices:
Thinking…
The expasion of the storage should not take a long time using my method for preventing expansion in between every disk swap.
The manual method of doing this expansion would be to create a mdraid5 of the four drives, adding these to the LVM configuration as pv, then adding that pv to the “volume_1” stripe. Unless the Synology decides to merge md2 and md3 (which I assume will be created using the 4x5TB partitions)…
Expanding the storage volume
When resyncing md4 (previously named md2) finished, a new mdraid using the four 5TB partitions was created, and a resync was initiated (as it’s not ZFS, this might be necessary even when there is “no data” to sync). As it looks like now, this step will take about 52 hours (going much slower than previous resyncs, so it might be a temporary low speed).
root@DS918:~# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4]
md2 : active raid5 sda6[3] sdd6[2] sdc6[1] sdb6[0]
14651252736 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/4] [UUUU]
[=>...................] resync = 5.1% (249940160/4883750912) finish=3159.2min speed=24445K/sec
md4 : active raid5 sda5[7] sdb5[6] sdd5[4] sdc5[5]
8776306368 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/4] [UUUU]
md1 : active raid1 sda2[3] sdd2[2] sdc2[1] sdb2[0]
2097088 blocks [16/4] [UUUU____________]
md0 : active raid1 sda1[0] sdb1[1] sdc1[3] sdd1[2]
2490176 blocks [16/4] [UUUU____________]
unused devices:
mdadm –detail /dev/md2 gives some more information:
root@DS918:~# mdadm --detail /dev/md2
/dev/md2:
Version : 1.2
Creation Time : Sun May 4 20:17:34 2025
Raid Level : raid5
Array Size : 14651252736 (13972.52 GiB 15002.88 GB)
Used Dev Size : 4883750912 (4657.51 GiB 5000.96 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Sun May 4 23:45:30 2025
State : active, resyncing
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : left-symmetric
Chunk Size : 64K
Resync Status : 5% complete
Name : DS918:2 (local to host DS918)
UUID : cc2a3e88:4f844ebd:2fbf5461:f29bbaf0
Events : 43
Number Major Minor RaidDevice State
0 8 22 0 active sync /dev/sdb6
1 8 38 1 active sync /dev/sdc6
2 8 54 2 active sync /dev/sdd6
3 8 6 3 active sync /dev/sda6
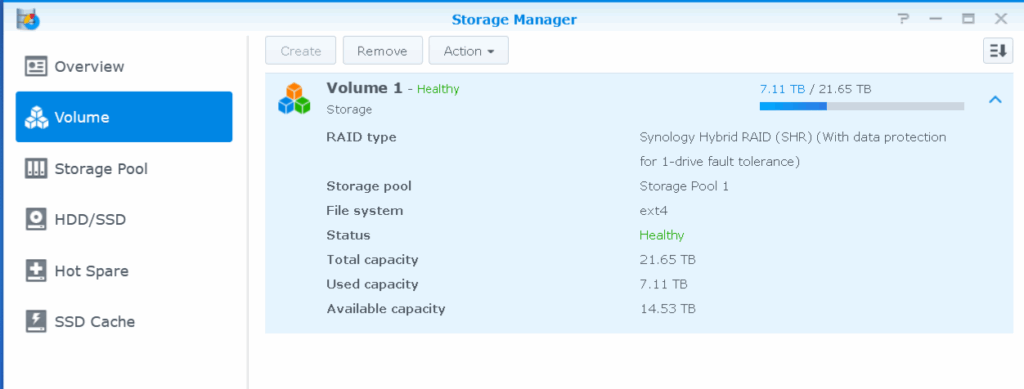
I also found out that the storage pool (but not the volume) has now been expanded to its final size of 21.7TB:
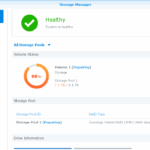
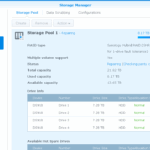
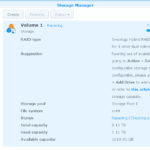
On the “Volume” page, I can go on creating a new volume,which is not what I want. I suppose expanding the current volume will be possible after the resync of the newly added space is done.
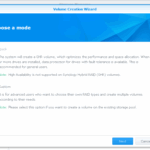
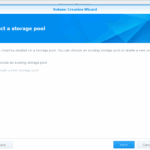
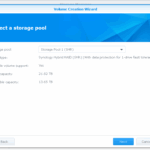
I cancelled on the last step where the volume was going to be created, as I want to expand the main storage volume instead.
On the “Linux” side (mdraid and LVM), I found out that the “Physical Volume” had been created and that volume had been added to the “Volume Group” vg1:
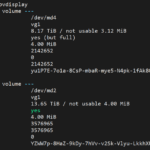
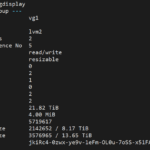
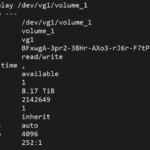
When md2 was fully synced
At the end of the the resync of md2, which took about 79 hours (estimated time was 52 hours, but the speed dropped during the resync, and the estimated time increased over the two following days), I was still not able to extend the storage volume from the location I expected it to be in (the “Action” drop-down button under “Volume” in “Storage Manager”). My mistake here was to not check “Configure” under that same drop-down button.
I added new drives to my Synology NAS, but the available capacity didn’t increase. What can I do?
So for DSM 6.2 (for the Fakenology), this is where it’s done:
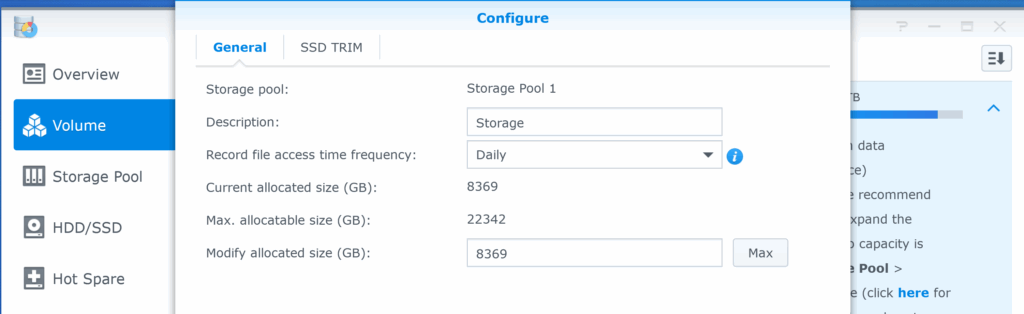
From the “Configuration” page, the volume size can be changed to any size greater than the current size, or to “max” which will add the newly created storage to the volume.
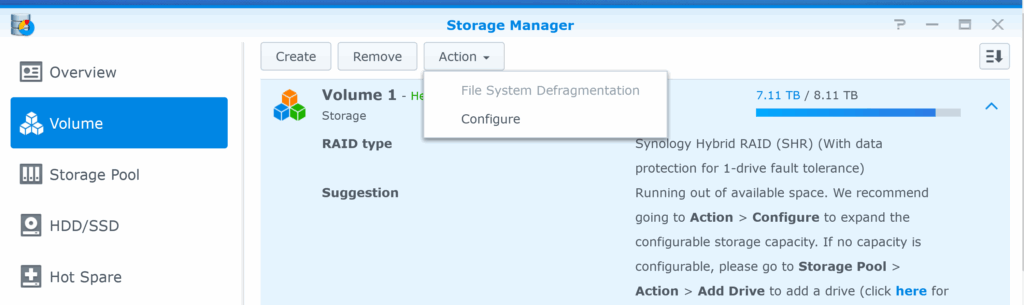
This option to change the size of the volume might have been there all the time (during synchronization), but in any case, it would probably had been better to leave it alone until first sync finalized anyway.
Now the mdraid volumes look like this:
root@DS918:/volume1# cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4]
md2 : active raid5 sda6[3] sdd6[2] sdc6[1] sdb6[0]
14651252736 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/4] [UUUU]
md4 : active raid5 sda5[7] sdb5[6] sdd5[4] sdc5[5]
8776306368 blocks super 1.2 level 5, 64k chunk, algorithm 2 [4/4] [UUUU]
md1 : active raid1 sda2[3] sdd2[2] sdc2[1] sdb2[0]
2097088 blocks [16/4] [UUUU____________]
md0 : active raid1 sda1[0] sdb1[1] sdc1[3] sdd1[2]
2490176 blocks [16/4] [UUUU____________]
unused devices:
At this stage, the storage pool is still untouched, but as shown in the images above, another pv has been added:
root@DS918:/volume1# cat /etc/lvm/backup/vg1
# Generated by LVM2 version 2.02.132(2)-git (2015-09-22): Thu May 8 03:03:03 2025
contents = "Text Format Volume Group"
version = 1
description = "Created *after* executing '/sbin/pvresize /dev/md2'"
creation_host = "DS918" # Linux DS918 4.4.59+ #25426 SMP PREEMPT Mon Dec 14 18:48:50 CST 2020 x86_64
creation_time = 1746666183 # Thu May 8 03:03:03 2025
vg1 {
id = "jkiRc4-0zwx-ye9v-1eFm-OL0u-7oSS-x51FA8"
seqno = 7
format = "lvm2" # informational
status = ["RESIZEABLE", "READ", "WRITE"]
flags = []
extent_size = 8192 # 4 Megabytes
max_lv = 0
max_pv = 0
metadata_copies = 0
physical_volumes {
pv0 {
id = "yu1P7E-7o1a-8CsP-mbaR-mye5-N4pk-1fAk8O"
device = "/dev/md4" # Hint only
status = ["ALLOCATABLE"]
flags = []
dev_size = 17552611584 # 8.17357 Terabytes
pe_start = 1152
pe_count = 2142652 # 8.17357 Terabytes
}
pv1 {
id = "YZWW7p-8HaZ-9kDy-7hVv-v2Sk-Vlyu-LkkhXU"
device = "/dev/md2" # Hint only
status = ["ALLOCATABLE"]
flags = []
dev_size = 29302504320 # 13.645 Terabytes
pe_start = 1152
pe_count = 3576965 # 13.645 Terabytes
}
}
logical_volumes {
syno_vg_reserved_area {
id = "3YdjJW-zkx6-DoKs-jEz0-kTXo-rpke-eYIw8P"
status = ["READ", "WRITE", "VISIBLE"]
flags = []
segment_count = 1
segment1 {
start_extent = 0
extent_count = 3 # 12 Megabytes
type = "striped"
stripe_count = 1 # linear
stripes = [
"pv0", 0
]
}
}
volume_1 {
id = "BFxwgA-3pr2-3BHr-AXo3-rJ6r-F7tP-vC7Te7"
status = ["READ", "WRITE", "VISIBLE"]
flags = []
segment_count = 1
segment1 {
start_extent = 0
extent_count = 2142649 # 8.17356 Terabytes
type = "striped"
stripe_count = 1 # linear
stripes = [
"pv0", 3
]
}
}
}
}
The next (and last step) is to add the new space to the storage volume (Volume 1). This is being done by adding a second segment to “volume_1”, which contains pv1 in the stripe list. of “volume_1”. When the segment has been added, the file system on “volume_1” is resized using the resize2fs command (this took a couple of minutes to finish).
root@DS918:/volume1# cat /etc/lvm/backup/vg1
# Generated by LVM2 version 2.02.132(2)-git (2015-09-22): Sun May 11 21:15:43 2025
contents = "Text Format Volume Group"
version = 1
description = "Created *after* executing '/sbin/lvextend --alloc inherit /dev/vg1/volume_1 --size 22878208M'"
creation_host = "DS918" # Linux DS918 4.4.59+ #25426 SMP PREEMPT Mon Dec 14 18:48:50 CST 2020 x86_64
creation_time = 1746990943 # Sun May 11 21:15:43 2025
vg1 {
id = "jkiRc4-0zwx-ye9v-1eFm-OL0u-7oSS-x51FA8"
seqno = 8
format = "lvm2" # informational
status = ["RESIZEABLE", "READ", "WRITE"]
flags = []
extent_size = 8192 # 4 Megabytes
max_lv = 0
max_pv = 0
metadata_copies = 0
physical_volumes {
pv0 {
id = "yu1P7E-7o1a-8CsP-mbaR-mye5-N4pk-1fAk8O"
device = "/dev/md4" # Hint only
status = ["ALLOCATABLE"]
flags = []
dev_size = 17552611584 # 8.17357 Terabytes
pe_start = 1152
pe_count = 2142652 # 8.17357 Terabytes
}
pv1 {
id = "YZWW7p-8HaZ-9kDy-7hVv-v2Sk-Vlyu-LkkhXU"
device = "/dev/md2" # Hint only
status = ["ALLOCATABLE"]
flags = []
dev_size = 29302504320 # 13.645 Terabytes
pe_start = 1152
pe_count = 3576965 # 13.645 Terabytes
}
}
logical_volumes {
syno_vg_reserved_area {
id = "3YdjJW-zkx6-DoKs-jEz0-kTXo-rpke-eYIw8P"
status = ["READ", "WRITE", "VISIBLE"]
flags = []
segment_count = 1
segment1 {
start_extent = 0
extent_count = 3 # 12 Megabytes
type = "striped"
stripe_count = 1 # linear
stripes = [
"pv0", 0
]
}
}
volume_1 {
id = "BFxwgA-3pr2-3BHr-AXo3-rJ6r-F7tP-vC7Te7"
status = ["READ", "WRITE", "VISIBLE"]
flags = []
segment_count = 2
segment1 {
start_extent = 0
extent_count = 2142649 # 8.17356 Terabytes
type = "striped"
stripe_count = 1 # linear
stripes = [
"pv0", 3
]
}
segment2 {
start_extent = 2142649
extent_count = 3576903 # 13.6448 Terabytes
type = "striped"
stripe_count = 1 # linear
stripes = [
"pv1", 0
]
}
}
}
}
root@DS918:/volume1# df -h Filesystem Size Used Avail Use% Mounted on /dev/md0 2.3G 987M 1.2G 45% / none 983M 0 983M 0% /dev /tmp 996M 944K 995M 1% /tmp /run 996M 8.2M 988M 1% /run /dev/shm 996M 4.0K 996M 1% /dev/shm none 4.0K 0 4.0K 0% /sys/fs/cgroup cgmfs 100K 0 100K 0% /run/cgmanager/fs /dev/vg1/volume_1 22T 7.2T 15T 33% /volume1 root@DS918:/volume1#

