I dug into the sqlite databases used by the JottaCloud client (and branded ones like Elgiganten) and found something that can be useful for other diggers…
This documentation is for the windows version of the client. The path to the database files and the path formats within the databases will differ for the client for other OSes.
11-Jan-2023: Updated example queries in the comments. Added ‘Find duplicates’.
Preparing
This method works for finding the location on the windows version:
Open the client interface, go to settings, then under the “General” tab, you will find a button that opens the log file location:
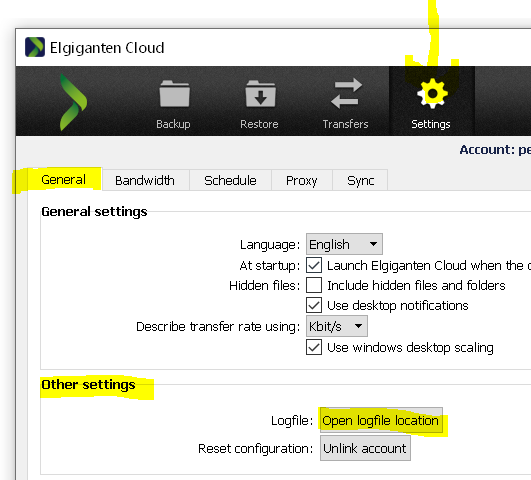
A window with the location ‘C:\Users\{myuser}\AppData\Roaming\Jotta\JottaWorld\log’ will be opened. Go to the parent directory, and there you will find the ‘db’ directory.
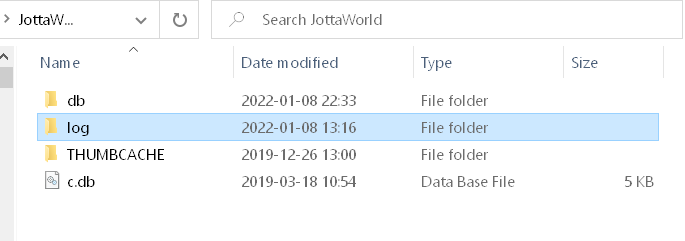
Keep this location open and QUIT the Jotta client (from the taskbar or any other effective method)
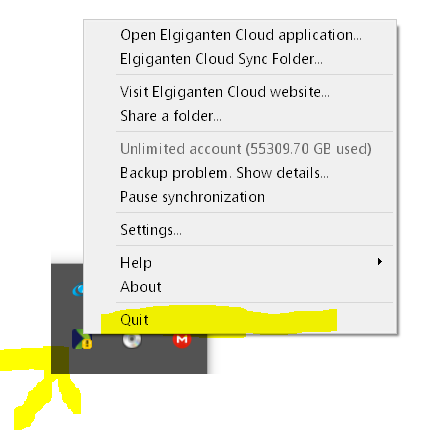
Copy the ‘db’ (or its parent ‘JottaWorld’) folder to a work- (or backup) location. NEVER do anything without having a backup copy of the ‘db’ folder, or even the whole ‘JottaWorld’ (parent) folder in case something goes wrong.
Examining the databases
From here, I will be examining each of the databases (.db files) and go through what I’ve found out. I will use the sqlite3 client supplied by microsoft-invented Ubuntu, the alternative is (on windows) to use a native sqlite3 client the same way, or just copy the ‘JottaWorld’ or ‘db’ directory to a computer with Linux (or any other real operating system) installed.
Basic sqlite3 usage
To open the database in sqlite3, simply use the sqlite3 command followed by the database name:
sqlite3 c.db
To show all tables in a database:
.tables
To show the table layout:
.schema {table name}
Select and update statements works basically as in other SQL clients.
c.db (outside the ‘db’ folder)
An empty database with a single table ‘c’, defined as:
CREATE TABLE c (id INTEGER PRIMARY KEY ASC AUTOINCREMENT,type integer, time integer, size integer, attempts integer, checksum string, path string, known );
The use of it is for me unknown (as the table is empty in my db).
This database was last changed almost two years before I stopped the Jotta client.
dl.db
Contains only one table ‘requests’ defined as
CREATE TABLE requests (id integer primary key autoincrement, callerid integer, localpath, remotepath, created integer, modified integer, revision integer, size integer, checksum varchar(32), queue integer, state integer, attempts integer, flags integer );
The use of it is for me unknown (as the table is empty in my db).
This database was last changed a week before I stopped the Jotta client.
dlsq.db
Database for the Jotta Sync folder. This folder is by default synced in full on all computers set up against the same Jotta account. There is no selective sync or OneDrive-like on-demand sync in Jotta, the only option is to completely disable the sync folder on the “Sync” tab in the settings. The sync folder location can be changed there too.
Tables:
| jwt_blockingevents | (empty) |
| jwt_files | Information about all files |
| jwt_folders | Information about all folders |
| jwt_queuedfiles | Files checksummed and queued for transfer |
| jwt_shares | Shared files and folders within the sync folder |
jwt_folders
The table is defined as:
CREATE TABLE jwt_folders (jwc_id INTEGER PRIMARY KEY ASC AUTOINCREMENT, jwc_stateid, jwc_remotepath, jwc_remotehash, jwc_localpath, jwc_localhash, jwc_basepath, jwc_relativepath, jwc_folderhash , jwc_state, jwc_parent, jwc_newpath);
| jwc_id | Folder id, used in the jwc_parent column and in jwc_files |
| jwc_stateid | empty on the data I have |
| jwc_remotepath | Path to the folder at Jotta, starting with ‘/{Jotta user name}/Jotta/Sync/’ |
| jwc_remotehash | md5sum of the folder (?) a folder cannot be hashed |
| jwc_localpath | The full local path to the folder |
| jwc_localhash | md5sum of the folder (?) a folder cannot be hashed |
| jwc_basepath | empty on the data I have |
| jwc_relativepath | Path relative to the Sync folder location, empty on many of the entries |
| jwc_folderhash | empty on the data I have |
| jwc_state | State as cleartext ‘Updated’ if all files are synced |
| jwc_parent | id (jwc_id) of parent folder |
| jwc_newpath | empty on the data I have |
jwt_files
The table is defined as:
CREATE TABLE jwt_files (jwc_id INTEGER PRIMARY KEY ASC AUTOINCREMENT, jwc_remotepath, jwc_remotesize INTEGER, jwc_remotehash, jwc_localpath, jwc_localsize INTEGER, jwc_localhash, jwc_relativepath, jwc_created INTEGER, jwc_modified INTEGER, jwc_updated INTEGER, jwc_status, jwc_checksum, jwc_state, jwc_uuid, jwc_revision , jwc_folderid, jwc_newpath);
| jwc_id | File id |
| jwc_remotepath | Path to the file at Jotta, starting with ‘/{Jotta user name}/Jotta/Sync/’ |
| jwc_remotesize | File size on the remote end (should match localsize) |
| jwc_remotehash | md5sum of something at the remote end |
| jwc_localpath | The full local path to the file |
| jwc_localsize | File size on the local side (should match remotesize) |
| jwc_localhash | md5sum of something at the local side |
| jwc_relativepath | Path relative to the remote location, empty on many of the entries |
| jwc_created | timestamp of file creation |
| jwc_modified | timestamp of file modification |
| jwc_updated | zero on all my files |
| jwc_status | empty on the data I have |
| jwc_checksum | file md5 checksum |
| jwc_state | either ‘UpdatedFileState’ or ‘MovingFileState’ (used on renamed files, see ‘jwc_newpath’) |
| jwc_uuid | don’t know, ‘{00000000-0000-0000-0000-000000000000}’ on most files |
| jwc_revision | 0, 1 or 11 on all my files |
| jwc_folderid | id (jwc_id from jwt_folders) of containing folder |
| jwc_newpath | New local name of a file renamed because of an upload error |
jwt_queuedfiles
The table is defined as:
CREATE TABLE jwt_queuedfiles (jwc_id INTEGER PRIMARY KEY ASC AUTOINCREMENT, jwc_remotepath, jwc_remotesize INTEGER, jwc_localpath, jwc_localsize INTEGER, jwc_relativepath, jwc_created INTEGER, jwc_modified INTEGER, jwc_status, jwc_checksum, jwc_revision INTEGER, jwc_queueid, jwc_type, jwc_hash , jwc_folderid);
It was empty in my current copy of the database, but it should be more or less like jwt_files (used only temporarily).
jwt_shares
The table is defined as:
CREATE TABLE jwt_shares (jwc_id INTEGER PRIMARY KEY ASC AUTOINCREMENT, jwc_shareid, jwc_localpath, jwc_remotepath, jwc_owner, jwc_members );
Mostly self-explanatory, except for the two fields I’m unable to explain 🙂
jwc_shareid is in the form of jwc_uuid given above, jwc_owner is probably some secret string about my user (at Jotta) that I’m not supposed to share. It’s an 24 character alphanumeric string.
jobs.db
Contains only one table ‘jobs’ defined as
CREATE TABLE jobs (id integer primary key autoincrement, status integer, uri, name, path, databasepath, files integer, bytes integer );
The use of it is for me unknown (as the table is empty in my db).
This database file was last changed almost a year before I stopped the client.
mm.db
Backup folders. This is the only table I have made manual changes to (I made the listed folder name in the GUI more obvious on some entries). Never change anything without having a backup, and never change anything while the client is running.
Tables:
| backup_schedule | The backup schedule (Schedule tab in settings) |
| backup_schedule_copy | Backup copy of the backup schedule |
| excludes | Files and folders excluded from backup |
| excludes_copy | Internal backup copy of the excludes table |
| mountpoints | All backup folders set in the client |
backup_schedule and backup_schedule_copy
The backup schedule in settings seems to be a very simplified one. By modifying the database it looks like they prepared to allow for different backup time settings every day (I don’t know if it works).
The table is defined as:
CREATE TABLE backup_schedule(id INTEGER PRIMARY KEY, mountpoint INTEGER, start_day TEXT, start_hour INTEGER, start_minute INTEGER, end_day TEXT, end_hour INTEGER, end_minute INTEGER);
All self-explanatory except “mountpoint”, which is set to “-1” when I create a schedule. If the schedule is set to any of the multi-day variants (“weekends”,”weekdays”,”everyday”) there will be multiple entries in the database, one for each day:
sqlite> select * from backup_schedule; 1|-1|Monday|2|0|Monday|7|0 2|-1|Sunday|2|0|Sunday|7|0 3|-1|Saturday|2|0|Saturday|7|0 4|-1|Wednesday|2|0|Wednesday|7|0 5|-1|Tuesday|2|0|Tuesday|7|0 6|-1|Friday|2|0|Friday|7|0 7|-1|Thursday|2|0|Thursday|7|0 sqlite> select * from backup_schedule; 1|-1|Sunday|2|0|Sunday|7|0 2|-1|Saturday|2|0|Saturday|7|0 sqlite>
My guess about the ‘mountpoint’ column (which is set to “-1” by the schedule settings in the client) is that it refers to the ‘mountpoints’ table, so theoretically it should be possible to create separate schedules for every one of the mountpoints by directly entering them into the database…
The ‘backup_schedule_copy’ table contains the schedule before making changes through the client.
excludes and excludes_copy
All files and folders that are excluded by the backup. This also includes the system and hidden files and folders that are not backed up. From the client settings, it is possible to include hidden files and folders.
The table is defined as:
CREATE TABLE excludes(id INTEGER PRIMARY KEY, mountpoint INTEGER, pattern VARCHAR(1024));
Not much to explain here. ‘mountpoint’ is set to ‘-1’, and I find no possible use for it to match an entry in the ‘mountpoints’ table. ‘pattern’ allows for simple pattern matching (*) for the full local path of a file or folder to exclude from backup.
mountpoints
This table contains all the backup folders defined in the client.
The table is defined as:
CREATE TABLE mountpoints(jwc_id INTEGER PRIMARY KEY ASC AUTOINCREMENT,jwc_name,jwc_path,jwc_device,jwc_description,jwc_status,jwc_location,jwc_type,jwc_ip,jwc_suspended );
| jwc_name | Name displayed in the client |
| jwc_path | The path for the folder to backup |
| jwc_device | Computer name (for the Jotta side ?) |
| jwc_description | Computer name |
| jwc_status | Status, can be any of the following: Scanning ScheduleWaiting AllGood Uploading QueuedForScan |
| jwc_location | ‘Local’ or ‘Remote’ |
| jwc_type | Zero on all my entries |
| jwc_ip | 127.0.0.1 for local paths, empty for remote |
| jwc_suspended | “Suspended” for paused backups, blank otherwise |
I find the content of jwc_status to more often be incorrect than correct, while writing this it is scanning one of my network drives, but in the database it says “Uploading”. Many entries are “Up to date” according to the client, but listed as different things in the db.
reque_c and reque_u
Two more sqlite3 database files that are without their extension (.db)
reque_c contains a table with queued uploads (scanned files, on queue for checksumming), which has the same definition as reque_u. As these files are queued for checksumming, the “checksum” field in the blob is an empty string. Content of the extraData fields in the blob is written to sm.db in (before) this stage.
reque_u contains a table with queued uploads (checksummed, waiting for upload slot):
CREATE TABLE uploads (id INTEGER PRIMARY KEY, tag INTEGER, blob BLOB );
id: just the entry id, duplicated (last value) in the blob
tag: the oddly named field for the mountpoint id (in mm.db), repeated in the blob
blob contains JSON array of file information:
{
"checksum": "6cd9bca0e441280fb72ff5cf6f7991b3",
"cre": 1657809534,
"extraData": {
"id": 9730953,
"parent": 12740
},
"localpath": "C:/Users/peo/Downloads/Toro Reelmaster 216 - Operators Manual - MODEL NO. 03410TE—70001 & UP.pdf",
"mod": 1657809535,
"remotepath": "/jfs/LAPTOP-3/Downloads/Toro Reelmaster 216 - Operators Manual - MODEL NO. 03410TE—70001 & UP.pdf",
"size": 1972185,
"tag": 9,
"timeout": 0
},
"id": 9907
}
Most content of the blob is self-explanatory if you have read until here.
checksum: the md5 checksum of the file
cre, mod: timestamp of creation and last modification
extraData:id is the new file id and extraData:parent is the folder containing the file (folders table in mm.db). This information was written to the database in the scanning phase (reque_c).
sm.db
Contains information on all backed up files
Tables:
| files | Information for all backed up files |
| folders | Information for all backed up folders |
| mountpoint_status | (empty) |
folders
The table is defined as:
CREATE TABLE folders (id integer primary key autoincrement, path text UNIQUE, state integer, parent integer, mountpoint integer, checksum varchar(20));
| path | Full local path to the folder |
| state | Contains a value of 1,2,5,6 or 7 in my database, have no idea of what it represents |
| parent | Id of parent folder (in this table) |
| mountpoint | mountpoint id in mm.db |
| checksum | md5 checksum on something (a folder cannot be checksummed) |
files
The table is defined as:
CREATE TABLE files (id integer primary key autoincrement, path text UNIQUE, parent integer, size integer, modified integer, created integer, checksum varchar(16), state integer, mountpoint integer);
| path | The full path of the backed up file |
| parent | the id of the containing folder (in folders table) |
| size | file size |
| modified | timestamp of modification |
| created | timestamp of creation |
| checksum | md5 checksum of file |
| state | Contains a value of 6 or 7 in my database, have no idea of what it represents |
| mountpoint | mountpoint id in mm.db |
So why all this trouble analyzing the database ?
I wanted an easy way of finding my files by its md5 checksum, that was one of the reasons. Another thing (not solved yet) is that I want to find out the way of recreating the share link for a specific file or folder within a public shared folder on my Jotta account (this without going through the web interface, I mean, it’s already shared inside an accessible folder).
Odd things noticed are that there are md5 checksums for folders, and three different ones in the sync folder (the jwt_files and jwt_folders tables in the dlsq.db), but for the individual files there is only the files’ real md5 checksum.
Anyway… that investigation will continue some other day…
Comment below if you find the way to calculate the share-id, or find it useful in any other way 🙂